
ScoreGeneratorを開発するにあたって、
- 楽譜を生成する技術(自動採譜)はどこまで研究が進んでいるのか?
- 入力に使用する音楽データはどのようなファイル形式がよいか?
が疑問として浮かびました。これらについて調査・考察した内容を紹介します。
音楽データの形式について
まずは代表的なデータ形式について整理します。本稿では、楽曲の音源が収録されたデータをオーディオと呼ぶことにし、MIDIデータと比較します。MIDIデータには音源そのものは収録されておらず、演奏の情報が記録されています。
- オーディオ
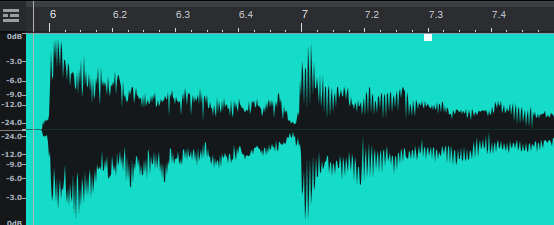
- リニアPCM形式
- アナログのオーディオ波形をサンプリング、量子化して記録した形式(非圧縮)
- ギターやマイクの音をDAWで取り入れた場合はこの形式になる
- ファイル形式としては、WAVファイル(拡張子は.wav)が代表的
- MP3形式
- リニアPCMから圧縮を行い、データ量を軽量化した形式
- MP3ファイルとして、Downloadコンテンツなどの一般的な楽曲ファイルに使用される
- リニアPCM形式
- MIDIデータ
- 電子楽器と演奏情報を通信するための規格。楽曲制作にも使用される
- 時間情報とともに下記の基本要素が記録されている(ピアノロールのイメージ)
- ノートナンバー:音の高さ (0~127)
- ベロシティ:音量 (0~127)
- ノートオン / ノートオフ:音(打鍵)のオン/オフ

- オーディオと比較してデータサイズが相当軽量である
- データとして入手が難しい
楽譜データの形式について(省略)
楽譜データについては他の記事で説明するとして、ここでは詳細を省略しますが、MusicXMLというフォーマットやABC記譜法という形式で表現されることが一般的です。
MucsicXML: https://www.w3.org/2021/06/musicxml40/
ABC記譜法: https://abcnotation.com/wiki/abc:standard:v2.1
どのデータ形式から楽譜データを生成するか
1.オーディオ(WAV or MP3) から楽譜データを直接生成する
MP3ファイルであれば一般的に流通しているため、例えば「MP3を入力としてMusicXMLが出力される」ような技術があれば最も良いと考えていたのですが、そのような例は見つかりませんでした。
MP3と比べると、非圧縮のWAVの方が入力に適していそうです。しかし、同様に、楽譜データを直接生成する(WAVとMusicXMLを紐づけて学習させる、WAVと楽譜の画像を紐づけて学習させる)例は見当たらず。想定はしていましたが、このようなダイナミックな手法はハードルが高いようです。
2.MIDIから楽譜データを生成する
MIDIは演奏情報を示しているため、楽譜との親和性が高いことが分かりました。MIDIの場合、機械学習や推定は不要で、ルールに基づいて楽譜に変換することになるため、より正確な結果が得られると考えられます。
MIDIをMusicXMLに変換する開発記事は複数ヒットします。また、自動作曲や楽曲特徴分類といった別の音楽系の機械学習トピックでも、MIDIが入力に使われることが多いことが分かりました。
しかし、データとして入手するのが難しいというデメリットは残ったままです。
3.オーディオからMIDI経由で楽譜データを生成する
オーディオをMIDIに変換できれば、2と組み合わせて楽譜データが生成できると考えられます。データの入手のしやすさを考慮して、オーディオからMIDIへの変換技術についても調べました。
3-1.音高推定
オーディオには音の高さ情報が直接的には記録されていません。オーディオ ⇒ MIDIの変換以前に、「音の高さを推定する」こと自体が研究の一分野になっています。
短時間の音の波形に対しては古くからフーリエ解析が主流となっています。近年では librosa というツールが便利で、機械学習時の前処理としても使用されています。librosaでwavファイルを解析し、得たスペクトログラムの画像に対して学習を行うことで、画像解析的アプローチで音の特徴量を学習させることができます。
librosa: https://librosa.org/doc/latest/index.html
解析対象の音の区間が長くなると難易度は上がります。2019年頃の論文でも、隠れマルコフモデルというキーワードの入った論文が数多くヒットしました。個人的には、この分野は近年までDeep Learningのアプローチは少なかったという印象を受けました。
3-2. Google Magenta (2018)
Google MagentaはアートにDeep Learningを活用するプロジェクトです。この中に、“Onsets and Frames” という自動採譜のテーマがあります。
Onsets and Framesでは、ソロのピアノ楽曲の演奏情報 (MIDI) と実際に演奏した音源(WAV)のデータセット (MAESTROデータセット) が公開されており、この組み合わせを Wave2Mid2Wave と呼ばれる手法で学習させることで、WAV ⇒ MIDIの変換精度を大きく向上させています。
Google Magenta: https://magenta.tensorflow.org/
Onsets and Frames: https://magenta.tensorflow.org/onsets-frames
3-3. DAWのAudio to MIDI 機能
オーディオ⇒MIDIについては、フリーソフトが複数配布されていたり、DAW (音楽制作ソフト)の一機能として装備されていたり、とツールとして使えるようになっているものも多くあります。中でも、Ableton LiveのMIDI変換機能が有名であるため、リンクを紹介しておきます。
オーディオをMIDIに変換する| Ableton Live: https://www.ableton.com/ja/manual/converting-audio-to-midi/
まとめ
サーベイにより、周辺知識について理解が深まりました。オーディオ⇒MIDIの変換については、精度が出ていることは分かったのですが、自分たちのプロジェクトには組み込みにくいだろうと判断し、ScoreGeneratorではMIDIを入力データに使用することにしました。